Membre du réseau Libre-entreprise
Le monde du Web et celui de l’impression ont décidément du mal à se rencontrer.
La prise en charge de l’impression est bien souvent très problématique dans le cadre d’un projet Web.
Dans la plupart des cas, il est possible de s’en sortir en utilisant les possibilités offertes par les feuilles de style CSS, mais le rendu final du document n’est pas garanti : les différents navigateurs interprètent la feuille de style selon leur humeur et cela ne fonctionne pas dans le cas de documents complexes.
Dans ce cas, l’unique solution est de produire un document au format PDF, unique garantie pour une impression de qualité.
Je vais donc décrire dans cet article la solution que nous avons mise en place dans le cadre du projet MAVISE.
La base de données MAVISE fournit les données sur l’ensemble des chaînes de télévision accessibles dans l’Union européenne.
Elle a été développée par Easter-eggs en collaboration avec l’Observatoire européen de l’audiovisuel (OEA) pour le compte de la Direction Générale de le Communication de la Commission Européenne.
Dans la première phase du projet, nous avons développé un système d’impression avec des feuilles de style.
Ce système ne donnait pas entièrement satisfaction au client.
En effet, les pages du projet étant très complexes, le résultat de l’impression produite par les différents navigateurs était très aléatoire (coupure en plein milieu d’un tableau, impression sur plusieurs pages et sauts de pages inexpliqués).
Le résultat n’était pas professionnel et il était difficile pour le client de produire un rapport papier avec les contenus de la base.
Nous avons donc proposé de mettre en place un export PDF pour l’ensemble des éléments de l’application.
Le travail pour produire des documents PDF consiste dans la plupart des cas à dessiner, à l’aide de différentes API, le contenu du document (texte, tableaux, graphiques et mise en page).
Les outils utilisés habituellement sont :
Il s’agit d’un travail long et fastidieux, qui consiste à fournir une suite d’instructions pour former le document.
Cette technique montre vite ses limites :
Dans le modèle MVC, qu’utilisent la plupart des applications Web, nous utilisons un système de template pour l’affichage (la vue).
Alors à quoi bon « coder » à nouveau la présentation des documents PDF ?
Nous avons donc proposé au client de bâtir le système d’impression des documents PDF sur un système de template.
Ce système repose sur le langage de programmation XSL-FO, les projets Apache FOP et Apache Cocoon.
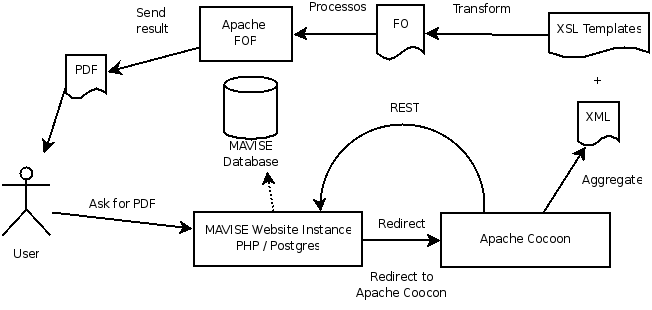
1. Lorsque l’utilisateur clique sur le lien PDF, il est redirigé vers Apache Cocoon ;
2. Cocoon récupère l’ensemble des informations directement sur le site Web via l’API REST ;
3. Il agrège les informations dans un document XML ;
4. Ce document est transformé en FO à l’aide d’une feuille de style XSLT ;
5. Le document est produit par Apache FOP ;
6. L’utilisateur obtient le document final.
L’architecture du système d’impression repose sur le fait que l’ensemble des variables manipulées par notre application est accessible à l’aide d’URL REST.
En effet, il est possible d’afficher le contenu des différentes variables manipulées par l’application à l’aide d’adresses URL spécifiques.
Voici un exemple de sortie :
<?xml version="1.0" encoding="UTF-8"?> <array> <is_admin /> <country> <id>1</id> <iso3166>FR</iso3166> <name>France</name> <enabled>t</enabled> <minimal_age_of_audience>14+</minimal_age_of_audience> </country> </array> ...
Il est donc possible de récupérer l’ensemble des informations du site à l’aide du protocole REST.
Nous avons aussi de très nombreux tableaux dans l’application. Pour les récupérer, nous utilisons le format XML natif du contrôleur de tableaux dhtmlxGrid. Voici un exemple de sortie : fichier XML pour dhtmlxGrid.
Pour récupérer l’ensemble des données du site dans un fichier XML, la directive « include » offerte par Cocoon a été utilisée :
$ cat /var/lib/tomcat5/webapps/cocoon/mavise/program/program.xml <?xml version="1.0"?> <page xmlns:i="http://apache.org/cocoon/include/1.0" name="program"> <i:include src="cocoon:/webui_program"> ... </i:include></page>
Cette directive dit à Cocoon, d’inclure le contenu qui se trouve à l’url cocoon :/webui_program, défini dans le fichier sitemap.xmap :
<!-- Webui -->
<map:match pattern="webui_*/*">
<map:generate src="http://localhost/{1}?id={2}&presenter=rest&filter=webui">
<map:serialize type="exml">
</map:serialize></map:generate></map:match>
Pour transformer les données contenues dans ce fichier, nous avons créé notre propre feuille de style XSLT, pour produire un document FO.
Cette feuille de style prend en compte la mise en forme des différentes données du site.
Grâce à ce système, l’ensemble de la mise en forme est centralisé dans un seul fichier.
Il est également possible d’ajouter du contenu statique dans le PDF à l’aide de balises dédiées, comme par exemple une balise copyright, qui sera transformée en un texte statique dans tous les documents PDF.
Voici le pipeline final pour produire des documents PDF :
<!-- PDF -->
<map:match pattern="*/*/*.pdf">
<map:generate src="{1}/{3}.xml">
<map:transform type="xslt" src="mk_id.xsl">
<map:parameter value="{2}" name="val">
</map:parameter></map:transform>
<map:transform type="include">
<map:parameter value="true" name="parallel">
<map:parameter value="true" name="support-caching">
<map:parameter value="600" name="expires">
</map:parameter></map:parameter></map:parameter></map:transform>
</map:generate></map:match>
Le point intéressant à noter dans ce pipeline est l’encodage des arguments passés via l’URL pour le document PDF.
En effet, les URL pour produire les PDF sont formés de la manière suivante :
http://mavise.obs.coe.int/cocoon/mavise/channel/2157/channel.pdf
L’URL contient le nom du module et l’identifiant de la chaîne.
Il est ainsi possible de passer d’autres arguments au système d’impression (comme par exemple changer l’orientation du document).
Au niveau des performances du système d’impression, nous n’avons pas une charge très importante sur la génération des documents PDF.
Mais la production des documents est une tâche complexe et nécessite donc de manière générale beaucoup de ressources.
Une chose intéressante à noter : la génération des documents PDF est plus rapide que l’affichage dans un navigateur !
Cela est lié au fait que les échanges de données se font en local sur le serveur, il y a donc moins de bande passante utilisée que dans le cas de l’affichage de cette même page par le navigateur.
Nous avons rencontré des difficultés avec la gestion des polices UTF-8. En effet, comme la base contient des données sur des chaînes de télévision et des entreprises Turques, nous avons eu besoin d’embarquer une police UTF-8 à l’intérieur du document.
Et visiblement cela pose des problèmes à certains lecteurs.
Voici quelques liens utiles qui nous ont aidé dans la réalisation de ce système d’impression :